深度神经网络实验报告
实验目的
- 分别使用全连接网络,卷积神经网络,循环神经网络去预测数据(图像分类) CIFAR-10 数据集
- 使用几个机器学习算法(自选)作为比较。 对预测结果进行分析。
- SVM算法
- KNN算法
CIFAR-10数据集介绍
数据集内容
CIFAR10数据集共有60000个样本,每个样本都是一张32*32像素的RGB图像(彩色图像),每个RGB图像又必定分为3个通道(R通道、G通道、B通道)。这60000个样本被分成了50000个训练样本和10000个测试样本。
CIFAR10数据集是用来监督学习训练的,那么每个样本就一定都配备了一个标签值(用来区分这个样本是什么),不同类别的物体用不同的标签值,CIFAR10中有10类物体,标签值分别按照0~9来区分,他们分别是飞机( airplane )、汽车( automobile )、鸟( bird )、猫( cat )、鹿( deer )、狗( dog )、青蛙( frog )、马( horse )、船( ship )和卡车( truck )。
CIFAR10数据集的内容,如下图所示:
| 物体种类 | 图片 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| airplane |  |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| automobile |  |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| bird |  |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| cat |  |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| deer |  |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| dog |  |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| frog |  |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| horse |  |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| ship |  |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| truck |  |
 |
 |
 |
 |
 |
 |
 |
 |
 |
数据集的结构组成
CIFAR10数据集结构组成可分为这四个部分:
- ·train_x:(50000, 32, 32, 3)——训练样本
- ·train_y:(50000, 1)——训练样本标签
- ·test_x:(10000, 32, 32, 3)——测试样本
- ·test_y:(10000, 1)——测试样本标签
数据集的下载方式
在Keras中已经内置了多种公共数据集,其中就包含CIFAR-10数据集,如图所示。
| 序号 | 名称 | 说明 |
|---|---|---|
| 1 | boston_housing | 波士顿房价数据集 |
| 2 | CIFAR10 | 10种类别的图片集 |
| 3 | CIFAR100 | 100种类别的图片集 |
| 4 | MNIST | 手写数字图片集 |
| 5 | Fashion-MNIST | 10种时尚类别的图片集 |
| 6 | IMDB | 电影点评数据集 |
| 7 | Reuters | 路透社新闻数据集 |
所以可以直接调用 tf.keras.datasets.cifar10,直接下载数据集。
使用方法如下:
from keras.datasets import cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()- 返回:
- 2元组:
- x_train,x_test:具有形状(num_samples ,3,32,32)的RGB图像数据的uint8数组。
- y_train,y_test:uint8具有形状(num_samples,)的类别标签数组(范围0-9中的整数)。
- 2元组:
深度神经网络的说明
全连接网络
简介
全连接神经网络(DNN)是最朴素的神经网络,它的网络参数最多,计算量最大。
DNN的结构不固定,一般神经网络包括输入层、隐藏层和输出层,一个DNN结构只有一个输入层,一个输出层,输入层和输出层之间的都是隐藏层。每一层神经网络有若干神经元(下图中蓝色圆圈),层与层之间神经元相互连接,层内神经元互不连接,而且下一层神经元连接上一层所有的神经元。
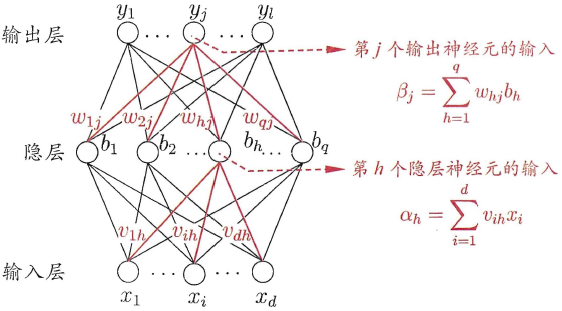
优点:由于DNN几乎可以拟合任何函数,所以DNN的非线性拟合能力非常强。往往深而窄的网络要更节约资源。
缺点:DNN不太容易训练,需要大量的数据,很多技巧才能训练好一个深层网络。
模型说明
创建模型的代码如下:
#构建模型
layers = []
layers.append(tf.keras.layers.Flatten())
for nodes in nodes_per_layer:
layers.append(keras.layers.Dense(nodes, activation=tf.nn.relu)) # 使用 l2 正则化 kernel_regularizer=tf.keras.regularizers.l2(l=0.0001)
layers.append(keras.layers.Dropout(dropout_rate))
layers.append(keras.layers.Softmax())
model = keras.Sequential(layers)
#编译模型
model.compile(optimizer=tf.train.AdamOptimizer(0.001),
loss='sparse_categorical_crossentropy',
metrics=['accuracy']) 我创建了一个 Keras中的Sequential 模型,包含了多个网络层:
模型的第一层是一个 Flatten 层,它将输入的多维数组展平为一维数组,以便于后面的全连接层使用。
模型包含了四个 Dense 层。Dense 层就是全连接层,每个节点都与上一层的所有节点连接。第一个 Dense 层有 512 个节点,使用 relu 作为激活函数。第二个 Dense 层有 256 个节点,也使用 relu 作为激活函数。第三个 Dense 层有 128 个节点,也使用 relu 作为激活函数。第四个 Dense 层有 64 个节点,也使用 relu 作为激活函数。在每两层中间插入一个dropout层,这样一来,第一层的输出将对第二层实现Dropout正则化,后续层与此类似。
模型的最后一层是一个 Softmax层,有 10 个节点。Softmax函数将多个标量映射为一个概率分布,其输出的每一个值范围在(0,1)。这在分类问题中很常用,因为概率值可以表示模型的置信度。
配置训练方法时,训练时用的优化器、损失函数和准确率评测标准如下:
- optimizer 优化器:选用Adam,学习率lr设置为0.001
- loss 损失函数:选用稀疏的分类交叉熵 sparse_categorical_crossentropy
- metrics 评价函数:选用准确率accuracy
训练模型
起初我训练模型时没有数据增强,代码如下:
overfitting_hist = model.fit(x_train, y_train, epochs=10, batch_size=64, validation_data=(x_test, y_test),
use_multiprocessing=True)
#绘制训练和测试准确率
plt.plot(overfitting_hist.history['acc'])
plt.plot(overfitting_hist.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
此时,训练精度远高于测试精度(高达35%),此外,测试精度要么是静态的,要么是下降的,这意味着模型严重过度拟合。训练速度很快,使模型达到 50% 左右,但是它之后开始过度拟合,所以我切换到对生成数据进行训练,这些数据速度较慢,但不太可能导致过度拟合。
因此,我切换到增强数据,在 50000 个样本上进行训练,在 10000 个样本上进行验证,代码如下;
augmented = datagen.flow(x_train, y_train, batch_size=512,shuffle=True)
hist = model.fit_generator(augmented, epochs=10,validation_data=(x_test,y_test))
#绘制精度曲线
plt.plot(hist.history['acc'])
plt.plot(hist.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy') 结果如图:

绘制出的测试和训练集的准确率图像如下:

从上图可以看出;一开始,测试精度优于训练精度,但在第一个时期之后,训练精度仅比测试精度高出 4%,这意味着模型不会过度拟合。
模型评估
模型在测试集上的准确率如下:

总结
一方面使用未增强的数据集进行训练会导致过度拟合;另一方面立即使用增强的数据集会导致欠拟合。因此,我想出的最好的方法是先使用未增强的数据进行训练,直到导致过度拟合,然后切换到增强数据。该模型在增强数据上进行训练的难度较小,因为它已经了解了类的许多主要特征,然后数据增强使学习变得更加困难,但不易过度拟合。
完整代码
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
import os
#超参数
epochs = 30
nodes_per_layer = [1024,512,256,128,64]
layers = []
batch_size = 64
dropout_rate = 0.3
num_classes = 10
#===========================
#一.加载和标准化数据
#===========================
#加载数据
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
#标准化图像
x_train = tf.map_fn(lambda image: tf.image.per_image_standardization(image), x_train, dtype=tf.float32)
x_train = tf.Session().run(x_train)
x_test = tf.map_fn(lambda image: tf.image.per_image_standardization(image), x_test, dtype=tf.float32)
x_test = tf.Session().run(x_test)
#===========================
#二.构建、编译模型
#===========================
#我没有使用 l2 正则化,因为它使使用生成的数据的学习速度变慢并且不会减少过度拟合
layers = []
layers.append(tf.keras.layers.Flatten())
for nodes in nodes_per_layer:
layers.append(keras.layers.Dense(nodes, activation=tf.nn.relu)) # 使用 l2 正则化 kernel_regularizer=tf.keras.regularizers.l2(l=0.0001)
layers.append(keras.layers.Dropout(dropout_rate))
layers.append(keras.layers.Softmax())
model = keras.Sequential(layers)
#编译模型
model.compile(optimizer=tf.train.AdamOptimizer(0.001),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
#===========================
#三.训练模型
#===========================
#1. 没有使用数据增强
#这种训练速度很快,使模型达到 50% 左右,但是它之后开始过度拟合,所以我切换到对生成数据进行训练,这些数据速度较慢,但不太可能导致过度拟合
overfitting_hist = model.fit(x_train, y_train, epochs=10, batch_size=64, validation_data=(x_test, y_test),
use_multiprocessing=True)
#绘制训练和测试准确率
plt.plot(overfitting_hist.history['acc'])
plt.plot(overfitting_hist.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
#数据生成
#定义数据生成器以生成更多样化的数据
datagen = keras.preprocessing.image.ImageDataGenerator(
featurewise_center=False,
featurewise_std_normalization=False,
samplewise_center=False,
samplewise_std_normalization=False,
rotation_range=7,
zoom_range=0.07,
width_shift_range=0.15,
height_shift_range=0.15,
shear_range=0.01,
horizontal_flip=True)
#初始化数据生成所需的变量
datagen.fit(x_train)
#2. 使用数据增强
#使用生成的数据训练模型以避免过度拟合
augmented = datagen.flow(x_train, y_train, batch_size=512,shuffle=True)
hist = model.fit_generator(augmented, epochs=10,validation_data=(x_test,y_test))
#绘制精度曲线
plt.plot(hist.history['acc'])
plt.plot(hist.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
#===========================
#四.评估模型
#===========================
test_loss, test_acc = model.evaluate(x_test, y_test)
print('Test accuracy:', test_acc)卷积神经网络
简介
如果用全连接神经网络处理大尺寸图像具有三个明显的缺点:
- 将图像展开为向量会丢失空间信息;
- 参数过多效率低下,训练困难;
- 大量的参数也很快会导致网络过拟合。
而使用卷积神经网络可以很好地解决上面的三个问题。
一个卷积神经网络主要由以下 5 层组成:
- 数据输入层/ Input layer
- 卷积计算层/ CONV layer
- ReLU 激励层 / ReLU layer
- 池化层 / Pooling layer
- 全连接层 / FC layer
模型说明
创建模型的代码如下:
model = tf.keras.models.Sequential()
#卷积层 32个3*3的卷积核 激活函数relu输入形状32*32*3
model.add(tf.keras.layers.Conv2D(32, (3, 3), activation="relu", input_shape=(32, 32, 3)))
#池化层 2*2
model.add(tf.keras.layers.MaxPooling2D((2, 2)))
#卷积层 64个3*3的卷积核 激活函数relu
model.add(tf.keras.layers.Conv2D(64, (3, 3), activation="relu"))
#池化层 2*2
model.add(tf.keras.layers.MaxPooling2D((2, 2)))
#卷积层 64个3*3的卷积核 激活函数relu
model.add(tf.keras.layers.Conv2D(64, (3, 3), activation="relu"))
#展平
model.add(tf.keras.layers.Flatten())
#全连接层 64个神经元 激活函数relu
model.add(tf.keras.layers.Dense(64, activation="relu"))
#全连接层 10个神经元 激活函数softmax
model.add(tf.keras.layers.Dense(10, activation="softmax")) 我创建了一个 Keras中的Sequential 模型,包含了多个网络层:
- 模型的第一部分包含了三个卷积层,分别包含32个3 * 3、 64 个 3 * 3 、64 个 3 * 3的卷积核,和两个2*2的池化层
- 模型包含了一个Flatten层,将前一层的输出展平为一维张量。
- 模型的最后包含了两个全连接层,一个全连接层有64个神经元,激活函数为relu;另一个全连接层有10个单元,激活函数为softmax。
训练模型
将epochs设置为40,在 50000 个样本上进行训练,在 10000 个样本上进行验证,代码如下:
history = model.fit(train_images, train_labels, epochs=40,
validation_data=(test_images, test_labels))

模型评估
模型在测试集上的准确率如下:

完整代码
import tensorflow as tf
import matplotlib.pyplot as plt
#===========================
#一.加载和标准化数据
#===========================
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.cifar10.load_data()
train_images, test_images = train_images / 255.0, test_images / 255.0
#===========================
#二.构建、编译模型
#===========================
model = tf.keras.models.Sequential()
#卷积层 32个3*3的卷积核 激活函数relu输入形状32*32*3
model.add(tf.keras.layers.Conv2D(32, (3, 3), activation="relu", input_shape=(32, 32, 3)))
#池化层 2*2
model.add(tf.keras.layers.MaxPooling2D((2, 2)))
#卷积层 64个3*3的卷积核 激活函数relu
model.add(tf.keras.layers.Conv2D(64, (3, 3), activation="relu"))
#池化层 2*2
model.add(tf.keras.layers.MaxPooling2D((2, 2)))
#卷积层 64个3*3的卷积核 激活函数relu
model.add(tf.keras.layers.Conv2D(64, (3, 3), activation="relu"))
#展平
model.add(tf.keras.layers.Flatten())
#全连接层 64个神经元 激活函数relu
model.add(tf.keras.layers.Dense(64, activation="relu"))
#全连接层 10个神经元 激活函数softmax
model.add(tf.keras.layers.Dense(10, activation="softmax"))
model.summary()
model.compile(optimizer="adam",
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=["accuracy"])
#===========================
#三.训练模型
#===========================
history = model.fit(train_images, train_labels, epochs=40,
validation_data=(test_images, test_labels))
plt.plot(history.history["accuracy"], label="accuracy")
plt.plot(history.history["val_accuracy"], label="val_accuracy")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
# plt.ylim([0.0, 1])
plt.title('model accuracy')
plt.legend()
#===========================
#四.评估模型
#===========================
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('Test accuracy:', test_acc)循环神经网络
简介
RNNs的目的使用来处理序列数据。在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题却无能无力。
RNNs之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。理论上,RNNs能够对任何长度的序列数据进行处理。但是在实践中,为了降低复杂性往往假设当前的状态只与前面的几个状态相关,下图便是一个典型的RNNs:

模型说明
创建模型的代码如下:
model = keras.Sequential([
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32, input_shape=(1024, 3), return_sequences=True)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32)),
tf.keras.layers.Dropout(0.25),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.25),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=['sparse_categorical_accuracy']) 我创建了一个 Keras中的Sequential 模型,包含了多个网络层:
- 模型的第一层是一个双向 LSTM 层,它具有 32 个神经元,并返回序列。
- 模型的第二层是一个双向 LSTM 层,它也具有 32 个神经元。
- 第三层是一个池化层,它可以防止过拟合。
- 第四层是一个 Flatten 层,它把输入展平。
- 第五层是一个全连接层,它具有 128 个神经元和 ReLU 激活函数。
- 第六层是一个池化层,防止过拟合。
- 第七层是一个全连接层,它具有 64 个神经元和 ReLU 激活函数。
- 最后一层是一个全连接层,它具有 10 个神经元,激活函数为 softmax 。
训练模型
将epochs设置为10,在 50000 个样本上进行训练,在 10000 个样本上进行验证,代码如下:
history = model.fit(train_images, train_labels, batch=32,epochs=10,
validation_data=(test_images, test_labels))
绘制出的图像如下;

模型评估
模型在测试集上的准确率如下:

完整代码
import tensorflow as tf
import matplotlib.pyplot as plt
#===========================
#一.加载和标准化数据
#===========================
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.cifar10.load_data()
train_images, test_images = train_images / 255.0, test_images / 255.0
#===========================
#二.构建、编译模型
#===========================
model = keras.Sequential([
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32, input_shape=(1024, 3), return_sequences=True)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32)),
tf.keras.layers.Dropout(0.25),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.25),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=['sparse_categorical_accuracy'])
#===========================
#三.训练模型
#===========================
history = model.fit(train_images, train_labels, batch=32,epochs=10,
validation_data=(test_images, test_labels))
plt.plot(history.history["accuracy"], label="accuracy")
plt.plot(history.history["val_accuracy"], label="val_accuracy")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
# plt.ylim([0.0, 1])
plt.title('model accuracy')
plt.legend()
#===========================
#四.评估模型
#===========================
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('Test accuracy:', test_acc)机器学习算法
SVM算法
简介
支持向量机(SVM)是一种广泛使用的监督学习算法,可用于分类和回归。它的工作原理是找到一条决策边界,将不同类别的数据尽可能分开。
使用 SVM 分类 CIFAR-10 数据集的一般步骤如下:
- 准备数据:将 CIFAR-10 数据集加载到 Python 中,并将其转换为适合模型使用的格式。可能需要对图像进行预处理,例如缩放或归一化。
- 选择 SVM 模型:选择要使用的 SVM 模型(例如线性 SVM 或非线性 SVM)和决策函数。
- 训练模型:使用训练数据训练 SVM 模型。
- 评估模型:使用测试数据评估SVM模型
模型构建
我构建的svm模型如下:
def svm(c, kernel='poly', degree=2):
if kernel == 'poly':
svm_model = SVC(kernel=kernel, degree=degree, C=c)
else:
svm_model = SVC(kernel=kernel, C=c)
svm_model.fit(X_train, y_train)
return svm_model 我使用 sklearn 中的 SVC,构建 SVM 分类模型,令核函数的默认参数为 poly 多项式核函数。
模型训练
当惩罚参数C为5时,模型的训练结果如下:

此时模型在测试集上的正确率为0.47
手动调节惩罚参数C,模型在测试集上的正确率也在不断变化如下:
| C | 1 | 3 | 5 | 7 | 10 | 50 | 100 |
|---|---|---|---|---|---|---|---|
| acc | 0.42 | 0.45 | 0.47 | 0.38 | 0.43 | 0.41 | 0.41 |
从上表可知,当C=5时正确率最高。
模型评估
模型在训练集和测试集上的准确率如下:

模型在测试集上的表现如下:

完整代码
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler, MinMaxScaler
import numpy as np
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
from time import time
import tensorflow as tf
from tensorflow import keras
#===========================
#加载和标准化数据
#===========================
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.cifar10.load_data()
X_train = X_train[:10000]
y_train = y_train[:10000]
X_test = X_test[:2000]
y_test = y_test[:2000]
print(X_train.shape)
print(X_test.shape)
X_train_length = X_train.shape[1] * X_train.shape[2] * X_train.shape[3]
X_train = np.array(X_train).reshape(X_train.shape[0], X_train_length)
X_test = np.array(X_test).reshape(X_test.shape[0], X_train_length)
print(X_train.shape)
print(X_test.shape)
#===========================
#构建、编译模型
#===========================
def svm(c, kernel='poly', degree=2):
if kernel == 'poly':
svm_model = SVC(kernel=kernel, degree=degree, C=c)
else:
svm_model = SVC(kernel=kernel, C=c)
svm_model.fit(X_train, y_train)
return svm_model
if __name__ == "__main__":
kernel = 'rbf'
c = 5.0
print('%s(C=%.1f):' % (kernel, c))
#===========================
#训练模型
#===========================
print('正在训练...')
start = time()
model = svm(c, kernel=kernel)
print('训练完成所需时间: %.2fs' % (time() - start))
#===========================
#评估模型
#===========================
print('Train accuracy: %.2f' % model.score(X_train, y_train))
print('Test accuracy: %.2f' % model.score(X_test, y_test))
# 测试集
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred, digits=4))KNN算法
简介
KNN算法的实现步骤如下:
计算待分类的测试数据的特征向量与已知类别的训练样本的特征向量的欧氏距离。距离公式为:

将距离从小到大排序。
去前k个值并统计k个值中每个类别出现的频数。
频数最大的训练样本的类别即为测试样本的与预测类别。
模型构建
调用 sklearn 中的 KNeighborsClassifier,设置 n_neighbors=10,即临近的节点数量 为 10。构建模型的代码如下:
knn = KNeighborsClassifier(n_neighbors=10)模型训练
模型训练过程如下:

模型评估
模型在训练集和测试集上的准确率如下:

完整代码
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
from time import time
import tensorflow as tf
#===========================
#加载和标准化数据
#===========================
(X_train, y_train), (X_test, y_test) =tf.keras.datasets.cifar10.load_data()
print(X_train.shape)
print(X_test.shape)
X_train_length = X_train.shape[1] * X_train.shape[2] * X_train.shape[3]
X_train = np.array(X_train).reshape(X_train.shape[0], X_train_length)
X_test = np.array(X_test).reshape(X_test.shape[0], X_train_length)
print(X_train.shape)
print(X_test.shape)
print('training...')
print("neighbors_settings:", 10)
start = time()
#===========================
#构建、编译模型
#===========================
knn = KNeighborsClassifier(n_neighbors=10)
#===========================
#训练模型
#===========================
knn.fit(X_train, y_train)
#===========================
#评估模型
#===========================
train_acc = knn.score(X_train, y_train)
test_acc = knn.score(X_test, y_test)
print('training finished in %.2fs' % (time() - start))
print('train_accuracy:', train_acc)
print('test_acccuacy:', test_acc)
y_pred = knn.predict(X_test)
print(classification_report(y_test, y_pred, digits=4))结果对比分析
可视化图像对比
不同深度神经网络的表现对比如下:
| 深度神经网络 | acc |
|---|---|
| 全连接网络 | |
| 卷积神经网络 | |
| 循环神经网络 | |
从以上结果可知,深度神经网络中,模型适配度:卷积神经网络>全连接网络>循环神经网络
acc对比
不同算法在测试集上的准确率如下:
| 算法 | accuracy |
|---|---|
| 全连接网络 | 0.6424 |
| 卷积神经网络 | 0.6864 |
| 循环神经网络 | 0.4893 |
| SVM算法 | 0.47 |
| KNN算法 | 0.3386 |
从以上结果可知,本实验所选取的方案中,模型适配度:卷积神经网络>全连接网络>循环神经网络>SVM算法>KNN算法
可以直观看出,本实验中深度学习模型效果好于机器学习模型。



